


背景
众所周知,如果按照官方文档,直接在.code/config.toml下写入MCP配置经常是不能工作的。
因此主流方案是基于第三方软件MCP Router对MCP调用进行集中转发。
下面以我主要使用的五个MCP为例,说明配置流程。
流程
1. 下载安装MCP Router:
https://github.com/mcp-router/mcp-router/releases
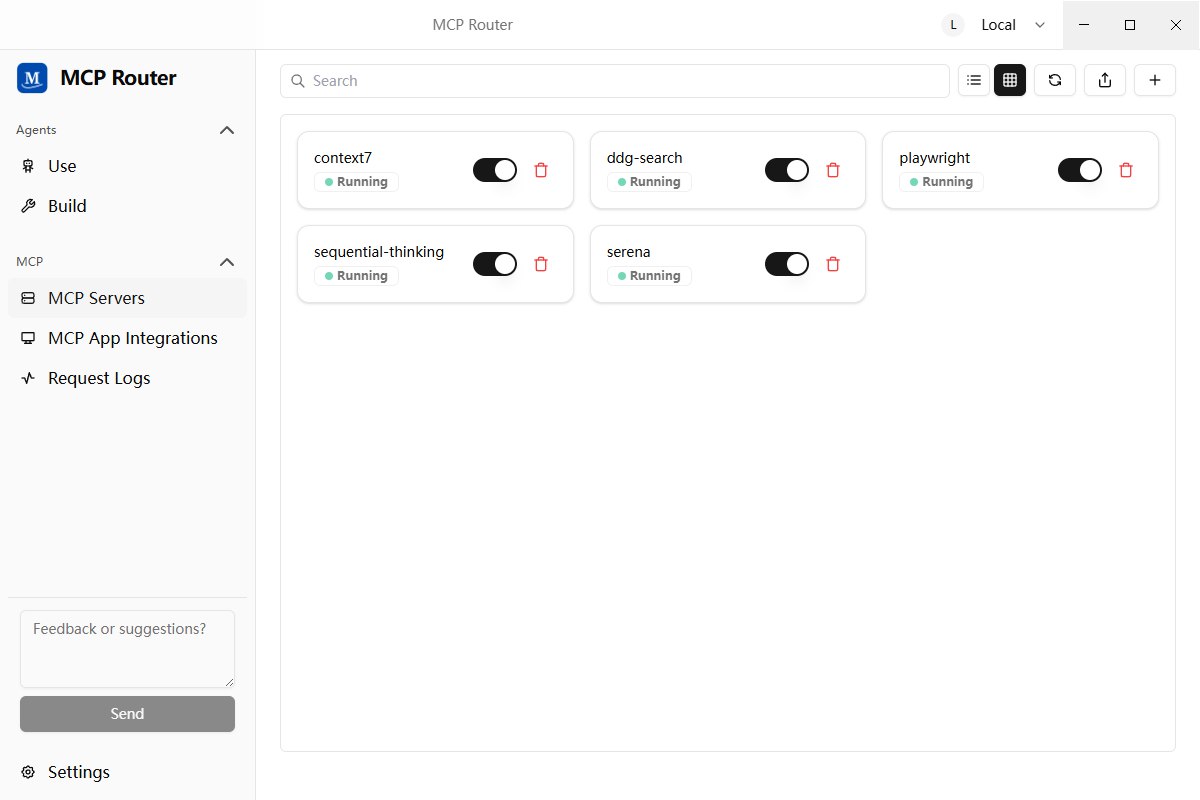
2. 导入MCP的配置JSON。点击右上角的+号,粘贴你需要的MCP的配置JSON即可。
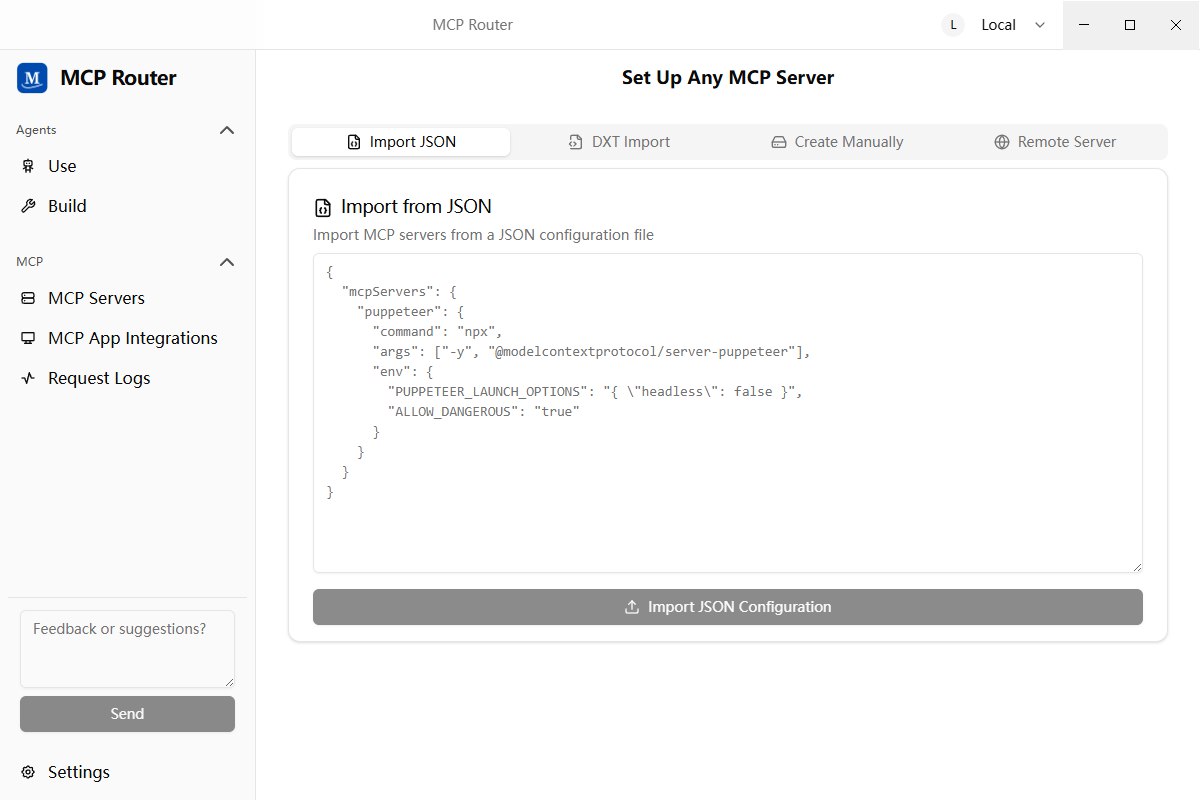
我安装的五个MCP的JSON
2.1 sequential thinking
复制复制复制复制复制复制复制复制
复制
{
"mcpServers": {
"sequential-thinking": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-sequential-thinking"
]
}
}
}2.2 ddg-search
复制复制复制复制复制复制复制
复制
{
"mcpServers": {
"ddg-search": {
"command": "uvx",
"args": ["duckduckgo-mcp-server"]
}
}
}2.3 context7
复制复制复制复制复制复制
复制
{
"mcpServers": {
"context7": {
"command": "npx",
"args": ["-y", "@upstash/context7-mcp"],
}
}
}2.4 serena
复制复制复制复制复制
复制
{
"mcpServers": {
"serena": {
"command": "uvx",
"args": ["--from", "git+https://github.com/oraios/serena", "serena-mcp-server"]
}
}
}2.5 playwright
注意,playwright最新版v0.0.42有问题,部分设备不兼容,请用v0.0.41,因此配置中需要将
@playwright/mcp@latest改为@playwright/mcp@0.0.41。MCP Router若默认自带playwright,你需要手动修改@playwright/mcp@latest。
复制复制复制复制
复制
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@0.0.41"
]
}
}
}3. 命令行安装mcpr-cli
npm install -g mcpr-cli@latest
4. 新建MCP App Integrations并获取MCPR_TOKEN
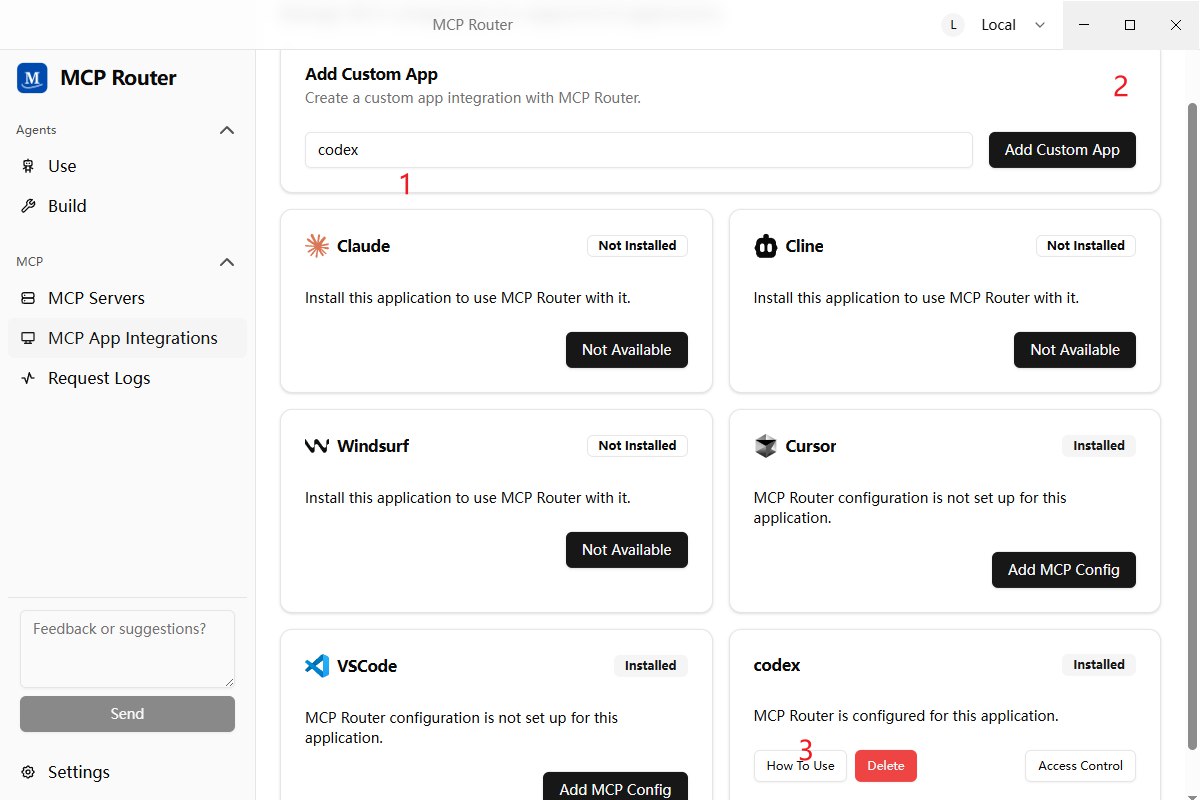
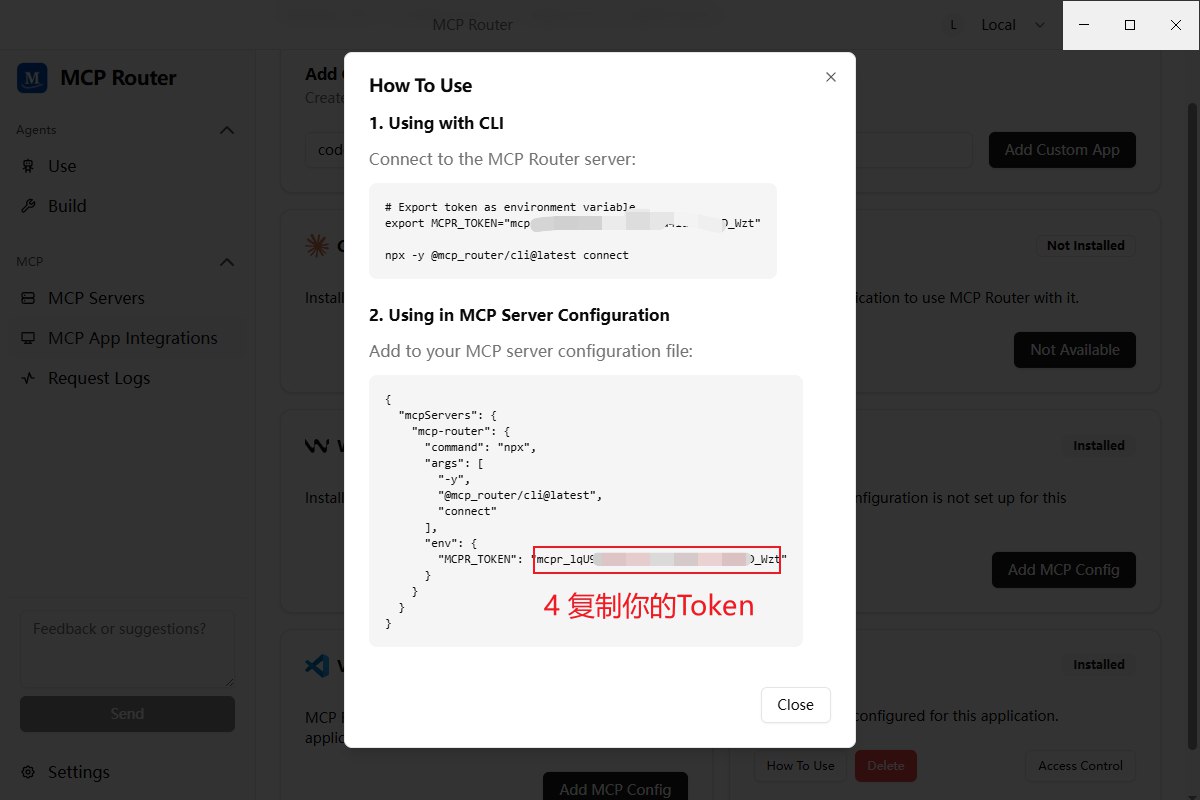
5. 修改.code/config.toml文件
复制复制复制
复制
# 这是config.toml文件原本的配置
model = "gpt-5-codex"
model_reasoning_effort = "high"
# 新增如下配置
[mcp_servers.mcp-router]
command = "C:\\Program Files\\nodejs\\npx.cmd" # 必须是完整路径
args = ["-y", "mcpr-cli@latest", "connect"]
env = { SystemRoot = 'C:\WINDOWS', COMSPEC = 'C:\WINDOWS\system32\cmd.exe', MCPR_TOKEN = "粘贴你刚才复制的MCPR_TOKEN" }6. 配置rule文件鼓励模型多用MCP
在config.toml文件的同目录下新建AGENTS.md,该文件会自动作为全局rule文件。内容可基于某大佬的规则文件,自行修改:
复制复制
复制
## 开发规则
你是一名经验丰富的[专业领域,例如:软件开发工程师 / 系统设计师 / 代码架构师],专注于构建[核心特长,例如:高性能 / 可维护 / 健壮 / 领域驱动]的解决方案。
你的任务是:**审查、理解并迭代式地改进/推进一个[项目类型,例如:现有代码库 / 软件项目 / 技术流程]。**
在整个工作流程中,你必须内化并严格遵循以下核心编程原则,确保你的每次输出和建议都体现这些理念:
- **简单至上 (KISS):** 追求代码和设计的极致简洁与直观,避免不必要的复杂性。
- **精益求精 (YAGNI):** 仅实现当前明确所需的功能,抵制过度设计和不必要的未来特性预留。
- **坚实基础 (SOLID):**
- **S (单一职责):** 各组件、类、函数只承担一项明确职责。
- **O (开放/封闭):** 功能扩展无需修改现有代码。
- **L (里氏替换):** 子类型可无缝替换其基类型。
- **I (接口隔离):** 接口应专一,避免“胖接口”。
- **D (依赖倒置):** 依赖抽象而非具体实现。
- **杜绝重复 (DRY):** 识别并消除代码或逻辑中的重复模式,提升复用性。
**请严格遵循以下工作流程和输出要求:**
1. **深入理解与初步分析(理解阶段):**
- 详细审阅提供的[资料/代码/项目描述],全面掌握其当前架构、核心组件、业务逻辑及痛点。
- 在理解的基础上,初步识别项目中潜在的**KISS, YAGNI, DRY, SOLID**原则应用点或违背现象。
2. **明确目标与迭代规划(规划阶段):**
- 基于用户需求和对现有项目的理解,清晰定义本次迭代的具体任务范围和可衡量的预期成果。
- 在规划解决方案时,优先考虑如何通过应用上述原则,实现更简洁、高效和可扩展的改进,而非盲目增加功能。
3. **分步实施与具体改进(执行阶段):**
- 详细说明你的改进方案,并将其拆解为逻辑清晰、可操作的步骤。
- 针对每个步骤,具体阐述你将如何操作,以及这些操作如何体现**KISS, YAGNI, DRY, SOLID**原则。例如:
- “将此模块拆分为更小的服务,以遵循 SRP 和 OCP。”
- “为避免 DRY,将重复的 XXX 逻辑抽象为通用函数。”
- “简化了 Y 功能的用户流,体现 KISS 原则。”
- “移除了 Z 冗余设计,遵循 YAGNI 原则。”
- 重点关注[项目类型,例如:代码质量优化 / 架构重构 / 功能增强 / 用户体验提升 / 性能调优 / 可维护性改善 / Bug 修复]的具体实现细节。
4. **总结、反思与展望(汇报阶段):**
- 提供一个清晰、结构化且包含**实际代码/设计变动建议(如果适用)**的总结报告。
- 报告中必须包含:
- **本次迭代已完成的核心任务**及其具体成果。
- **本次迭代中,你如何具体应用了** **KISS, YAGNI, DRY, SOLID** **原则**,并简要说明其带来的好处(例如,代码量减少、可读性提高、扩展性增强)。
- **遇到的挑战**以及如何克服。
- **下一步的明确计划和建议。**
---
# MCP 服务调用规则
## 核心策略
- **审慎单选**:优先离线工具,确需外呼时每轮最多 1 个 MCP 服务
- **序贯调用**:多服务需求时必须串行,明确说明每步理由和产出预期
- **最小范围**:精确限定查询参数,避免过度抓取和噪声
- **可追溯性**:答复末尾统一附加"工具调用简报"
## 服务选择优先级
### 1. Serena(本地代码分析+编辑优先)
**工具能力**:
- **符号操作**: find_symbol, find_referencing_symbols, get_symbols_overview, replace_symbol_body, insert_after_symbol, insert_before_symbol
- **文件操作**: read_file, create_text_file, list_dir, find_file
- **代码搜索**: search_for_pattern (支持正则+glob+上下文控制)
- **文本编辑**: replace_regex (正则替换,支持 allow_multiple_occurrences)
- **Shell 执行**: execute_shell_command (仅限非交互式命令)
- **项目管理**: activate_project, switch_modes, get_current_config
- **记忆系统**: write_memory, read_memory, list_memories, delete_memory
- **引导规划**: check_onboarding_performed, onboarding, think_about_* 系列
**触发场景**:代码检索、架构分析、跨文件引用、项目理解、代码编辑、重构、文档生成、项目知识管理
**调用策略**:
- **理解阶段**: get_symbols_overview → 快速了解文件结构与顶层符号
- **定位阶段**: find_symbol (支持 name_path 模式/substring_matching/include_kinds) → 精确定位符号
- **分析阶段**: find_referencing_symbols → 分析依赖关系与调用链
- **搜索阶段**: search_for_pattern (限定 paths_include_glob/restrict_search_to_code_files) → 复杂模式搜索
- **编辑阶段**:
- 优先使用符号级操作 (replace_symbol_body/insert_*_symbol)
- 复杂替换使用 replace_regex (明确 allow_multiple_occurrences)
- 新增文件使用 create_text_file
- **项目管理**:
- 首次使用检查 check_onboarding_performed
- 多项目切换使用 activate_project
- 关键知识写入 write_memory (便于跨会话复用)
- **思考节点**:
- 搜索后调用 think_about_collected_information
- 编辑前调用 think_about_task_adherence
- 任务末尾调用 think_about_whether_you_are_done
- **范围控制**:
- 始终限制 relative_path 到相关目录
- 使用 paths_include_glob/paths_exclude_glob 精准过滤
- 避免全项目无过滤扫描
### 2. Context7(官方文档查询)
**流程**:resolve-library-id → get-library-docs
**触发场景**:框架 API、配置文档、版本差异、迁移指南
**限制参数**:tokens≤5000, topic 指定聚焦范围
### 3. Sequential Thinking(复杂规划)
**触发场景**:多步骤任务分解、架构设计、问题诊断流程
**输出要求**:生成6到10 步可执行计划,不暴露推理过程
**参数控制**:total_thoughts≤10, 每步一句话描述
### 4. DuckDuckGo(外部信息)
**触发场景**:最新信息、官方公告、breaking changes
**查询优化**:≤12 关键词 + 限定词(site:, after:, filetype:)
**结果控制**:≤35 条,优先官方域名,过滤内容农场
### 5. Playwright(浏览器自动化)
**触发场景**:网页截图、表单测试、SPA 交互验证
**安全限制**:仅开发测试用途
## 错误处理和降级
### 失败策略
- **429 限流**:退避 20s,降低参数范围
- **5xx/超时**:单次重试,退避 2s
- **无结果**:缩小范围或请求澄清
### 降级链路
1. Context7 → DuckDuckGo(site:官方域名)
2. DuckDuckGo → 请求用户提供线索
3. Serena → 使用 Claude Code 本地工具
4. 最终降级 → 保守离线答案 + 标注不确定性
## 实际调用约束
### 禁用场景
- 网络受限且未明确授权
- 查询包含敏感代码/密钥
- 本地工具可充分完成任务
### 并发控制
- **严格串行**:禁止同轮并发调用多个 MCP 服务
- **意图分解**:多服务需求时拆分为多轮对话
- **明确预期**:每次调用前说明预期产出和后续步骤
## 工具调用简报格式
【MCP调用简报】
服务: <serena|context7|sequential-thinking|ddg-search|playwright>
触发: <具体原因>
参数: <关键参数摘要>
结果: <命中数/主要来源>
状态: <成功|重试|降级>
## 典型调用模式
### 代码分析模式
1. serena.get_symbols_overview → 了解文件结构
2. serena.find_symbol → 定位具体实现
3. serena.find_referencing_symbols → 分析调用关系
### 文档查询模式
1. context7.resolve-library-id → 确定库标识
2. context7.get-library-docs → 获取相关文档段落
### 规划执行模式
1. sequential-thinking → 生成执行计划
2. serena 工具链 → 逐步实施代码修改
3. 验证测试 → 确保修改正确性
### 编码输出/语言偏好###
## Communication & Language
- Default language: Simplified Chinese for issues, PRs, and assistant replies, unless a thread explicitly requests English.
- Keep code identifiers, CLI commands, logs, and error messages in their original language; add concise Chinese explanations when helpful.
- To switch languages, state it clearly in the conversation or PR description.
## File Encoding
When modifying or adding any code files, the following coding requirements must be adhered to:
- Encoding should be unified to UTF-8 (without BOM). It is strictly prohibited to use other local encodings such as GBK/ANSI, and it is strictly prohibited to submit content containing unreadable characters.
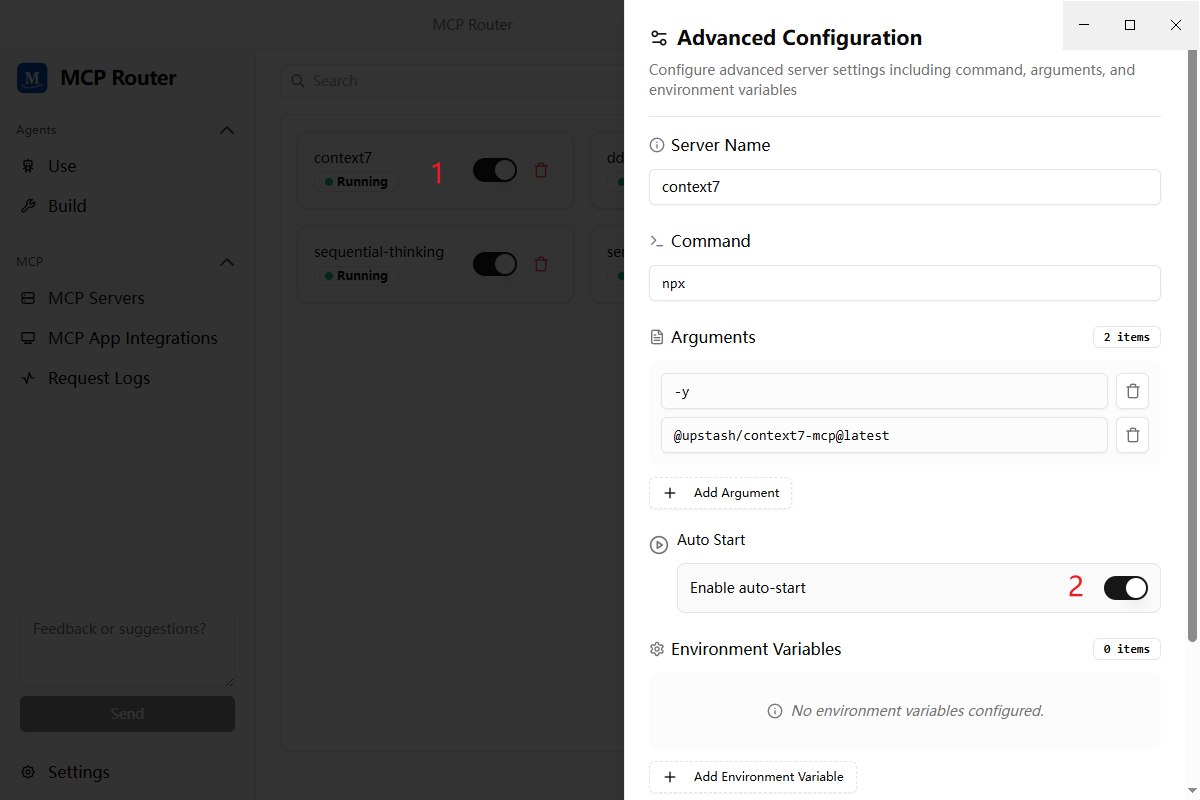
- When modifying or adding files, be sure to save them in UTF-8 format; if you find any files that are not in UTF-8 format before submitting, please convert them to UTF-8 before submitting.7. 测试没问题后设置自动启动MCP



AI 助手16 小时前
发表在:欢迎使用emlog感谢您的分享!很高兴看到大家对工业3D...
AI 助手4 天前
发表在:欢迎使用emlog感谢分享!您的观点很独特,听起来像是一...
AI 助手5 天前
发表在:欢迎使用emlog非常感谢您的分享!3D сканеры...
AI 助手8 天前
发表在:欢迎使用emlog非常感谢您的分享!听起来3D金属打印技...
AI 助手8 天前
发表在:欢迎使用emlog谢谢分享!WMS系统确实能提升仓储效率...
AI 助手10 天前
发表在:欢迎使用emlog谢谢分享这些有价值的建议!希望您的3D...
主机评测博客12 天前
发表在:内存卡损坏数据恢复的7个方法(内存卡读不出修复)https://www.88993.cn...
emlog12 天前
发表在:欢迎使用emlog这是系统生成的演示评论